
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 조합
- 재귀함수
- pandas 메소드
- DataFrame
- barh
- 자료구조
- pandas filter
- pandas
- 등차수열
- MacOS
- 리스트
- INSERT
- 문제풀이
- 파이썬
- plt
- 기계학습
- 스터디노트
- Slicing
- 순열
- matplotlib
- python
- Folium
- Machine Learning
- 통계학
- numpy
- maplotlib
- tree.fit
- 머신러닝
- SQL
- 등비수열
Archives
- Today
- Total
코딩하는 타코야끼
[Pandas] 5강_Pandas_DataFrame_합치기 본문
728x90
반응형
1. 데이터프레임 합치기
- 두개 이상의 DataFrame을 합쳐 하나의 DataFrame으로 만든다.
- inner join
- 행이 같아야 join 가능.
- outer join
- 행이 같지 않아도 join 가능.(단, 행의 값이 맞지 않으면 Nan output)
📍 수직결합
- 단순결합으로 여러개의 DataFrame들의 같은 컬럼끼리 수직으로 합친다.

📍 수평결합
- 연관성 있는 여러 데이터를 하나로 합쳐서 조회하는 JOIN 처리를 한다.
- 합치려는 DataFrame의 index 나 특정 컬럼의 값이 같은 행 끼리 합친다. !중요!

📍 데이터셋 읽기
- stocks_2016.csv, stocks_2017.csv, stocks_2018.csv : 년도별 보유 주식
- stocks_info.csv : 주식 정보
📍 concat() 이용
- 수직, 수평 결합 모두 지원한다.
- 하나의 데이터셋을 여러 DataFrame으로 나눈 것을 하나의 DataFrame으로 합칠 때 사용한다.
🌓 수직 결합 (행이 늘어나도록 합친다.)
- 컬럼명이 같은 열끼리 합친다.
- 같은 column 명이 없는 열들도 결과 DataFrame에 들어간다.(default)
- full outer join개념
🌓 수평 결합(열이 늘어나도록 합친다.)
- index명이 같은 행 끼리 합친다. (equi-join)
- 같은 index명이 없는 행들도 결과 DataFrame에 들어간다.(default)
- full outer join
pd.concat([stock_2016, stock_2017, stock_2018],
axis = 1,# 수평결합 - 1번 축 방향으로 합친다. => 행 index이름이 같은 것 끼리 합니다.
join = 'inner') # 양쪽에 모두 있는 것들만 붙인다. = > inner
result2 = pd.concat([stock_2016, stock_2017, stock_2018],ignore_index=True)
# 'ignore_index=True'는 대상 dataframe들의 index이름은 무시하고(버리고) 붙인다.
# ==> index명은 0 ~ 1씩 자동증가하는 값으면 변경.
result2
result3 = pd.concat([stock_2016, stock_2017, stock_2018], keys = ['2016년', '2017년', '2018년'])
#각각의 DataFrame을 구분할 수 있는 index를 추가한다.(멀티 index)
result3
result3.loc['2016년'] # 2016년 DataFrame 추출 가능.
result3.loc[('2018년',0)] # 2018년의 0번 인덱스 추출.
>>>
# 2018 추출 값
Symbol AAPL
Shares 40
Low 135
High 170
Name: (2018년, 0), dtype: object
🌓 pd.concat(objs, [, key=리스트]), axis=0, join='outer' )
- 매개변수
- objs: 합칠 DataFrame들을 리스트로 전달
- keys=[] 를 이용해 합친 행들을 구분하기 위한 다중 인덱스 처리
- axis
- 0 또는 index : 수직결합
- 1 또는 columns : 수평결합
- join:
- 합치는 방식으로 다음 문자열을 값으로 설정한다.
- 'outer'(기본값): full outer join
- 'inner': inner join (동일한 index명, column명 끼리 합친다.)
- 합치는 방식으로 다음 문자열을 값으로 설정한다.

📍 조인을 통한 DataFrame 합치기
- 연관성있는 둘 이상의 DataFrame을 하나로 합친다.
- ex) 고객과 주문정보, 교수와 수업정보, 직원과 부서정보
- join()
- 2개 이상의 DataFrame을 조인할 때 사용
- merge()
- 2개의 DataFrame의 조인만 지원
🌓 join( )
- dataframe객체.join(others, how='left', lsuffix='', rsuffix='')
- df_A.join(df_b), df_A.join([df_b, df_c, df_d])
- 두개 이상의 DataFrame들을 조인 할 수 있다.
- 조인 기준: index가 같은 값인 행끼리 합친다. (equi-join)
- 조인 기본 방식: Left Outer Join - 'left'dataframe' 이 기준
- 매개변수
- lsuffix, rsuffix
- 조인 대상 DataFrame에 같은 이름의 컬럼이 있으면 에러 발생.
- 같은 이름이 있는 경우 붙일 접미어 지정
- how :조인방식. 'left', 'right', 'outer', 'inner'. left가 기본
- lsuffix, rsuffix
stock_info.join(stock_2017, lsuffix = '_info', rsuffix = '_2016')
# 행 index 이름이 같은 행끼리 join => 이 데이터프레임들은 Symbol 컬럼값이 같은 행끼리 join 해야된다.
join_df = stock_info.set_index('Symbol').join(stock_2017.set_index('Symbol'),how = 'inner')
#inner join
stock_2017.set_index('Symbol').join(stock_info.set_index('Symbol'),how = 'right')
# right outer join (stock_info의 모든 행이 다 join 된다.)
stock_2016.add_suffix("_접미어") # 뒤에 붙는 명령어
stock_2016.add_prefix('접두어_') # 앞에 붙는 명령어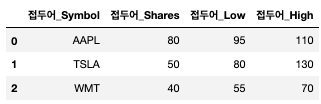
🌓 merge( )
- inner 방식이 이 기본방식이다.
- df_a.merge(df_b)
- 두개의 DataFrame간의 조인만 가능하다.
- 조인 기준
- 같은 컬럼명을 기준으로 equi-join을 하는 것이 기본이다.
- 조인기준을 다양하게 정할 수 있다.
- 컬럼, index등을 기준으로 같은 행끼리 join 하도록 설정할 수 있다.
- 조인 기본 방식
- inner join
- how 매개변수를 이용해 변경이 가능하다.
- 조인 기준
- dataframe.merge(합칠dataframe, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False)
- 매개변수
- on : 같은 컬럼명이 여러개일때 join 대상 컬럼을 선택
- right_on, left_on : 조인할 때 사용할 왼쪽,오른쪽 Dataframe의 컬럼명.
- left_index, right_index: 조인 할때 index를 사용할 경우 True로 지정
- how : 조인 방식. 'left', 'right', 'outer', 'inner'. 기본: inner
- suffixes: 두 DataFrame에 같은 이름의 컬럼명이 있을 경우 구분을 위해 붙인 접미어를 리스트로 설정
- 생략시 x, y를 붙인다.
- 하나의 데이터셋을 어떤 특정행 또튼 특정열을 기준으로 단순해 분리 한 경우를 합치는 경우 concat() 사용
- 수직 결합일 경우는 concat()을 사용해야 한다.
- 서로 연관성 있는 다른 데이터셋을 결합해서 보는 경우 join(), merge()를 사용한다. (Join)
- 두 개 이상의 DataFrame을 조인할 때는 하는 경우 : join() 사용
- 두개의 DataFrame을 조인할 때는 merge() 를 사용한다. => 컨트롤이 편하다.
stock_2016.merge(stock_info, how = 'right') # 같은 컬럼명(Symbol)의 값을 기준으로 join
stock_info.merge(stock_2016, how = 'left') # join 방식: inner join

stock_info.merge(stock_2016_2,
left_on = 'Symbol', # 왼쪽 (stock_info) 에서는 Symbol 컬럼을 join 기준.
right_index = True) # 오른쪽(stock_2016_2) 에서는 index 이름을 join 기준.

stock_2016_2.merge(stock_info, left_index = True, right_on = "Symbol")
# 같은 이름의 컬럼이 여러개 일때 Join 기준 컬럼을 일부만 선택할떄 on을 사용.
stock_2016.merge(stock_2018, on = 'Symbol', suffixes=['_2016','_2018'])

반응형
'[T.I.L] : Today I Learned > Pandas' 카테고리의 다른 글
| [Pandas] 7-1강_시계열 데이터 다루기 (0) | 2023.04.30 |
|---|---|
| [Pandas] 6강_DataFrame_재구조화 (0) | 2023.04.24 |
| [Pandas] 4-2강_pivot_table 및 일괄처리 메소드 (0) | 2023.04.19 |
| [Pandas] 4-1강_groupby 관련 메소드 (0) | 2023.04.19 |
| [Pandas] 3강_Pandas 정렬 집계 (0) | 2023.04.18 |
'[T.I.L] : Today I Learned/Pandas' Related Articles
more



