
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- SQL
- barh
- pandas
- python
- INSERT
- 기계학습
- 등차수열
- 리스트
- 머신러닝
- 순열
- numpy
- Machine Learning
- 재귀함수
- pandas filter
- 문제풀이
- MacOS
- Folium
- pandas 메소드
- DataFrame
- 파이썬
- matplotlib
- maplotlib
- Slicing
- tree.fit
- 통계학
- plt
- 등비수열
- 조합
- 자료구조
- 스터디노트
Archives
- Today
- Total
코딩하는 타코야끼
[Pandas] 4-2강_pivot_table 및 일괄처리 메소드 본문
728x90
반응형
1. pivot_table()
- 엑셀의 pivot table 기능을 제공하는 메소드.분류별 집계(Group으로 묶어 집계)를 처리하는 함수로 group으로 묶고자 하는 컬럼들을 행과 열로 위치시키고 집계값을 값으로 보여준다.역할은 groupby()를 이용한 집계와 같은데 여러개 컬럼을 기준으로 groupby 를 할 경우 집계결과를 읽는 것이 더 편하다.(가독성이 좋다)

- DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
🌓 매개변수
- index
- 문자열 또는 리스트. index로 올 컬럼들 => groupby였으면 묶었을 컬럼
- columns
- 문자열 또는 리스트. column으로 올 컬럼들 => groupby였으면 묶었을 컬럼 (index/columns가 묶여서 groupby에 묶을 컬럼들이 된다.)
- values
- 문자열 또는 리스트. 집계할 대상 컬럼들
- aggfunc
- 집계함수 지정. 함수, 함수이름문자열, 함수리스트(함수이름 문자열/함수객체), dict: 집계할 함수
- 기본(생략시): 평균을 구한다. (mean이 기본값)
- fill_value, dropna
- fill_value: 집계시 NA가 나올경우 채울 값
- dropna: boolean. 컬럼의 전체값이 NA인 경우 그 컬럼 제거(기본: True)
- margins/margins_name
- margin: boolean(기본: False). 총집계결과를 만들지 여부.
- margin_name: margin의 이름 문자열로 지정 (생략시 All)
📍 1개의 컬럼을 grouping 해서 집계
- 항공사별 비행시간의 평균
- 사용컬럼
- grouping할 컬럼
- AIRLINE: 항공사
- 집계대상컬럼
- AIR_TIME
- grouping할 컬럼
- 집계: mean
flights.groupby('AIRLINE')['AIR_TIME'].mean()
flights.pivot_table(index="AIRLINE",values="AIR_TIME",aggfunc = "mean") # 반환 :DataFrame
flights.pivot_table(columns="AIRLINE",values="AR_TIME") # aggfunc의 기본은: 평균!!!!
flights.pivot_table(index="AIRLINE", values="AIR_TIME", aggfunc = "mean", margins=True, margins_name='총계')
# 되도록이면 사용할 컬럼이 2개 이상일때만 피벗테이블 사용!!!

📍 2개의 컬럼을 grouping 해서 집계
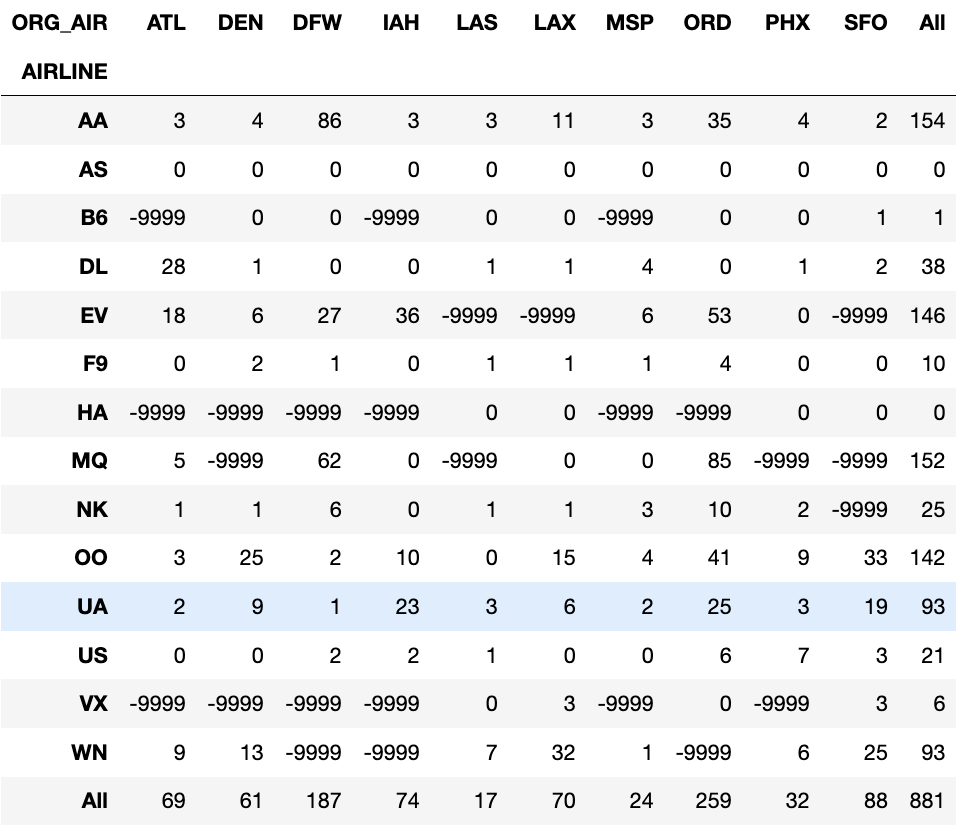
- 항공사/출발공항코드 별 취소 총수 (1이 취소이므로 합계를 구한다.)
- 사용컬럼
- grouping할 컬럼
- AIRLINE: 항공사
- ORG_AIR: 출발 공항코드
- 집계대상컬럼
- CANCELLED: 취소여부 - 1:취소, 0: 취소안됨
- grouping할 컬럼
- 집계: sum
flights.pivot_table(index="AIRLINE", columns="ORG_AIR", values="CANCELLED",aggfunc="sum",
fill_value=-9999, #결측치를 대체할 값. (결측치 - 그 그룹으로 묶인 행이 없음.)
margins= True)
📍 3개 이상의 컬럼을 grouping해서 집계2
- 항공사/월/출발공항코드 별 최대/최소 연착시간
- grouping할 컬럼
- AIRLINE:항공사
- MONTH:월
- ORG_AIR: 출발지 공항
- 집계 대상컬럼
- ARR_DELAY: 연착시간
- 집계 : min, max
flights.groupby(["AIRLINE","MONTH","ORG_AIR"])['ARR_DELAY'].agg(['min','max'])

2. apply() - Series, DataFrame의 데이터 일괄 처리
- 데이터프레임의 행들과 열들 또는 Series의 원소들에 공통된 처리를 할 때 apply 함수를 이용하면 반복문을 사용하지 않고 일괄 처리가 가능하다.
📍 DataFrame.apply(함수, axis=0, args=(), **kwarg)
- 인수로 행이나 열을 받는 함수를 apply 메서드의 인수로 넣으면 데이터프레임의 행이나 열들을 하나씩 함수에 전달한다.
- 매개변수
- 함수: DataFrame의 행들 또는 열들을 전달할 함수
- axis: 0-컬럼(열)을 전달, 1-행을 전달 (기본값 0)
- args: 함수에 행/열 이외에 전달할 매개변수를 위치기반(순서대로) 튜플로 전달
- *kwarg: 함수에 행/열 이외에 전달할 매개변수를 키워드 인자로 전달
📍 Series.apply(함수, args=(), **kwarg)
- 인수로 Series의 원소들을 받는 함수를 apply 메소드의 인수로 넣으면 Series의 원소들을 하나씩 함수로 전달한다.
- 매개변수
- 함수: Series의 원소들을 전달할 함수
- args: 함수에 원소 이외에 전달할 매개변수를 위치기반(순서대로) 튜플로 전달
- *kwarg: 함수에 원소 이외에 전달할 매개변수를 키워드 인자로 전달
🌓 DataFrame 만들기
import numpy as np
import pandas as pd
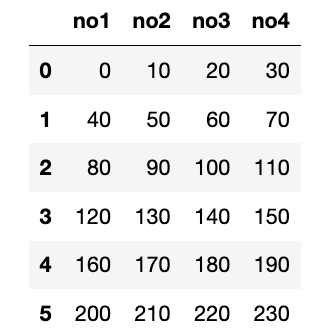
a = np.arange(24).reshape(6,4) # agrange(24) 0 ~ 23 1씩 증가하는 정수로 구성된 1차원 배열
# reshape(6,4) 배열의 형태(shape)을 변경 - 6 x 4 2차원 배열로 변환.
df = pd.DataFrame(a, columns=['no1', 'no2', 'no3', 'no4'])
df

🌓 함수 정의
def func1(x):
return x * 10
🌓 apply 적용
# DataFrame 적용
df.apply(func)
# Series 적용
df['no2'].apply(func)
>>>
0 10
1 50
2 90
3 130
4 170
5 210
Name: no2, dtype: int64
3. cut()/qcut() - 연속형(실수)을 범주형으로 변환
📍 cut( )
- 지정한 값을 기준으로 구간을 나눠 그룹으로 묶는다.
- pd.cut(x, bins,right=True, labels=None)
🌓 매개변수
- x: 범주형으로 바꿀 대상. 1차원 배열형태(Series, 리스트, ndarray)의 자료구조
- bins: 범주로 나눌때의 기준값(구간경계)들을 리스트로 묶어서 전달한다.
- right: 구간경계의 오른쪽(True-기본)을 포함할지 왼쪽(False)을 포함할지
- labels: 각 구간(범주)의 label을 리스트로 전달
- 생략하면 범위를 범주명으로 사용한다. (ex: (10, 20], ()-포함안함, []-포함)
📍 qcut( )
- 대상배열의 최대값 ~ 최소값을 지정한 개수의 동등한 size(원소의개수)가 되도록 나눈다.
- pd.qcut(x, q, labels)
🌓 매개변수
- x: 나눌 대상. 1차원 배열형태의 자료구조
- q: 나눌 개수
- labels: 각 구간(범주)의 label을 리스트로 전달
🌓 DataFrame 정의
import numpy as np
np.random.seed(0)
age = np.random.randint(1, 100, size= 12) # 1 ~ 99 사이의 난수 30개
tall = np.round(np.random.normal(170, 10, size=30), 2)
# 평균: 170, 표준편차: 10 인 정규분포를 따르는 난수 30개. 대부분의 난수가 170-10*2 ~ 170+10*2 범위. 평균에 가까운 값들이 많이 생성.
df = pd.DataFrame({
'나이': age,
'키': tall })
df

🌓 cut( ) 적용
나이대 = pd.cut(df['나이'],bins=3, #df['나이'] => 같은 범위로 3등분
right = False, # closed 방향을 지정. default : right = True
labels=['청년', '장년', '노년']) # 각 범주의 label 을 지정.
df['나이대'] = 나이대
df

🌓 qcut( ) 적용
키대 = pd.qcut(df['키대'] # 나눌 대상
, q = 3 # 몇 개로 나눌지
, labels = ['작은키', '중간키', '큰키'])
df['키대'] = 키대
df

반응형
'[T.I.L] : Today I Learned > Pandas' 카테고리의 다른 글
| [Pandas] 6강_DataFrame_재구조화 (0) | 2023.04.24 |
|---|---|
| [Pandas] 5강_Pandas_DataFrame_합치기 (0) | 2023.04.24 |
| [Pandas] 4-1강_groupby 관련 메소드 (0) | 2023.04.19 |
| [Pandas] 3강_Pandas 정렬 집계 (0) | 2023.04.18 |
| [Pandas] 2-2강_Pandas DataFrame(행, 열의 값 조회 및 변경) (0) | 2023.04.13 |
'[T.I.L] : Today I Learned/Pandas' Related Articles
more



