
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- SQL
- INSERT
- 등차수열
- tree.fit
- 기계학습
- 등비수열
- plt
- matplotlib
- Machine Learning
- pandas filter
- 순열
- 문제풀이
- DataFrame
- 머신러닝
- 통계학
- 재귀함수
- MacOS
- pandas
- 자료구조
- 스터디노트
- Slicing
- python
- Folium
- barh
- pandas 메소드
- 조합
- numpy
- 리스트
- 파이썬
- maplotlib
Archives
- Today
- Total
코딩하는 타코야끼
[스터디 노트] Week9_3일차 [심화_5 ~ 7] - SQL 본문
728x90
반응형
1. Primary KEY
- 테이블의 각 레코드를 식별
- 중복되지 않은 고유값을 포함
- NULL 값을 포함할 수 없음
- 테이블 당 하나의 기본키를 가짐
📍 PRIMARY KEY 생성 문법-1
CREATE TABLE person(
pid INT NOT NULL,
name VARCHAR(16),
age INT,
sex CHAR,
PRIMARY KEY (pid)
);

📍 여러개의 칼럼 기본키 설정
# 여러개의 칼럼을 기본키로 설정하는 경우
CREATE TABLE animal(
name VARCHAR(16) NOT NULL,
type VARCHAR(16) NOT NULL,
age INT,
PRIMARY KEY (name, type)
);

📍 PRIMARY KEY 삭제
ALTER TABLE person
DROP PRIMARY KEY;
# 여러개의 컬럼이여도 삭제는 동일
ALTER TABLE animal
DROP PRIMARY KEY
📍 PRIMARY KEY 생성 문법-2
# 기본키 1개 설정
ALTER TABLE person
ADD PRIMARY KEY (pid);
# 기본키 여러개 설정
ALTER TABLE animal
ADD CONSTRAINT PK_animal PRIMARY KEY (name, type);2. FOREIGN KEY (외래키)
- 한 테이블을 다른 테이블과 연결해주는 역할이며,
- 참조되는 테이블의 항목은 그 테이블의 기본키 (혹은 단일값)

📍Table 생성 시 외래키 설정
CREATE TABLE orders(
oid INT NOT NULL,
order_no VARCHAR(16),
pid INT,
PRIMARY KEY (oid),
CONSTRAINT PK_person FOREIGN KEY (pid) REFERENCES person(pid)
);
❗️CREATE TABLE 에서 FOREIGN KEY를 지정하는 경우, CONSTRAINT 를 생략할 수 있다.
CREATE TABLE job(
jid INT NOT NULL,
name VARCHAR(16),
pid INT,
PRIMARY KEY (jid),
FOREIGN KEY (pid) REFERENCES person(pid)
);📍 자동 생성된 CONSTRAINT 를 확인하는 방법
SHOW CREATE TABLE job;
📍FOREIGN KEY 삭제 문법
ALTER TABLE orders
DROP FOREIGN KEY PK_person;❗️ Table 이 생성된 이후에도 ALTER TABLE 을 통해 FOREIGN KEY 를 지정할 수 있다
ALTER TABLE orders
ADD FOREIGN KEY (pid) REFERENCES person(pid);
📍 따라하기
- 다음과 같이 study_id 가 PRIMARY KEY, patient_id 가 person 테이블의 pid 와 연결된 FOREIGN KEY 로 지정된 study 테이블을 생성하세요.
- 생성한 테이블의 PRIMARY KEY 를 삭제하세요.
- 생성한 테이블의 FOREIGN KEY 를 삭제하세요.
- study 테이블의 patient_id 를 person 테이블의 pid 와 연결된 FOREIGN KEY 로 등록하세요.
- study 테이블의 study_id 를 PRIMARY KEY로 등록하세요.

# 1번
CREATE TABLE study(
study_id INT NOT NULL,
study_date DATE,
study_time TIME,
patient_id INT,
PRIMARY KEY (study_id),
FOREIGN KEY (patient_id) REFERENCES person(pid)
);# 2번
ALTER TABLE study
DROP PRIMARY KEY;
# 3번
ALTER TABLE study
DROP FOREIGN KEY study_ibfk_1;
# 4번
ALTER TABLE study
ADD FOREIGN KEY (patient_id) REFERENCES person(pid);# 5번
ALTER TABLE study
ADD PRIMARY KEY (study_id);3. Aggregate Functions (집계함수)
- 여러 칼럼 혹은 테이블 전체 칼럼으로부터 하나의 결과값을 반환하는 함수
- SQL에서 여러 행의 데이터를 하나의 결과 값으로 요약하는 데 사용됩니다.
- 이러한 함수는 주로 GROUP BY 절과 함께 사용되며, 데이터 분석과 보고에 매우 유용합니다.

📍 COUNT
- COUNT( ) 함수는 테이블의 행 수를 반환합니다.
SELECT COUNT(*) FROM police_station;
SELECT COUNT(DISTINCT police_station) FROM crime_status;
# crime_type 은 총 몇 가지?
SELECT COUNT(DISTINCT crime_type) FROM crime_status;
📍SUM
- SUM() 함수는 특정 열의 모든 값을 더합니다.
# 범죄 총 발생건수는?
SELECT SUM(case_number) FROM crime_status
WHERE status_type = '발생';
# 살인의 총 발생건수는?
SELECT SUM(case_number) FROM crime_status
WHERE crime_type = '살인' AND status_type = '발생';
# 중부 경찰서에서 검거된 총 범죄 건수는?
SELECT SUM(case_number) FROM crime_status
WHERE police_station = '중부' AND status_type = '검거';
📍 AVG
- AVG( ) 함수는 특정 열의 평균 값을 계산합니다.
# 평균 폭력 검거 건수는?
SELECT AVG(case_number) FROM crime_status
WHERE crime_type = '폭력' AND status_type = '검거';
# 중부경찰서 범죄 평균 발생 건수
SELECT AVG(case_number) FROM crime_status
WHERE police_station = '중부' AND status_type = '발생';
📍 MIN
- MIN() 함수는 특정 열의 최솟값을 찾아주는 함수.
# 강도 발생 건수가 가장 적은 경우 몇 건?
SELECT MIN(case_number) FROM crime_status
WHERE crime_type = '강도' AND status_type = '발생';
📍 MAX
- MAX() 함수는 특정 열의 최댓값을 찾아주는 함수.
# 강남 경찰서에서 가장 많이 발생한 범죄 건수는?
SELECT MAX(case_number) FROM crime_status
WHERE police_station = '강남' AND status_type = '발생';
📍 GROUP BY
- 그룹화하여 데이터를 조회를 한다.
# 경찰서 별로 총 발생 범죄 건수를 검색
SELECT police_station, SUM(case_number) 발생건수 FROM crime_status
WHERE status_type = '발생'
GROUP BY police_station
ORDER BY 발생건수 DESC
LIMIT 5;
# 경찰서 별로 평균 범죄 검거 건수를 검색
SELECT police_station, AVG(case_number) 평균검거건수 FROM crime_status
WHERE status_type = '검거'
GROUP BY police_station
ORDER BY 평균검거건수 DESC
limit 5;📍 HAVING
- 조건에 집계함수가 포함되는 경우 WHERE 대신 HAVING 사용

# 경찰서 별로 발생한 범죄 건수의 합이 4000 건보다 보다 큰 경우를 검색
SELECT police_station, SUM(case_number) FROM crime_status
WHERE status_type = '발생'
GROUP BY police_station
HAVING SUM(case_number) >= 4000;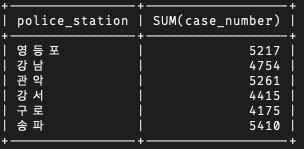
# 경찰서 별로 발생한 폭력과 절도의 범죄 건수 평균이 2000 이상인 경우를 검색
SELECT police_station, AVG(case_number) FROM crime_status
WHERE crime_type IN ('폭력', '절도') AND status_type = '발생'
GROUP BY police_station
HAVING AVG(case_number) >= 2000;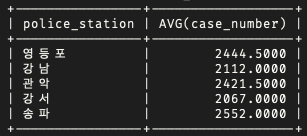
반응형
'zero-base 데이터 취업 스쿨 > 스터디 노트' 카테고리의 다른 글
| [스터디 노트] Week10_1일차 [기본] - 통계학 (2) | 2023.09.11 |
|---|---|
| [스터디 노트] Week9_4일차 [심화_8 ~ 10] - SQL (0) | 2023.09.04 |
| [스터디 노트] Week9_2일차 [심화_3 ~ 4] - SQL (0) | 2023.09.04 |
| [스터디 노트] Week9_1일차 [심화_1 ~ 2] - SQL (0) | 2023.09.04 |
| [스터디 노트] Week8_4일차 [basic_12 ~ 14] - SQL (0) | 2023.08.25 |
'zero-base 데이터 취업 스쿨/스터디 노트' Related Articles
more



