
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- numpy
- MacOS
- pandas 메소드
- 머신러닝
- maplotlib
- python
- 통계학
- DataFrame
- 파이썬
- pandas filter
- Slicing
- SQL
- pandas
- barh
- 리스트
- 재귀함수
- Folium
- tree.fit
- matplotlib
- 스터디노트
- 자료구조
- 기계학습
- 문제풀이
- Machine Learning
- 조합
- 등비수열
- 순열
- 등차수열
- plt
- INSERT
Archives
- Today
- Total
코딩하는 타코야끼
[ML] 2-1강_머신러닝 분석 - Iris 분석 본문
728x90
반응형
1. Iris(붓꽃) 예측모델

- 프랑스 국화
- 꽃말 : 좋은 소식, 잘 전해 주세요, 사랑의 메세지, 변덕스러움
📍 머신러닝의 Helloworld
- 데이터 과학에서 Iris DataSet
- 아이리스 품종 중 Setosa, Versicolor, Virginica 분류에 대한 로널드 피셔의 1936년 논문에서 사용된 데이터 셋.

- 꽃받침(Sepal)과 꽃잎(Petal)의 길이 너비로 세개 품종을 분류

📍 데이터셋 확인하기
🌓 scikit-learn 내장 데이터셋 가져오기
- scikit-learn은 머신러닝 모델을 테스트 하기위한 데이터셋을 제공한다.
- 이런 데이터셋을 Toy dataset이라고 한다.
- 패키지 : sklearn.datasets
- 함수 : load_xxxx()
from sklearn.datasets import load_iris
iris = load_iris() # 데이터를 메모리에 loading => Bunch => Dictionary 같은 것.(딕셔너리는 아님.)
type(iris)
>>>
sklearn.utils._bunch.Bunch🌓 scikit-learn 내장 데이터셋의 구성
- scikit-learn의 dataset은 딕셔너리 구조의 Bunch 클래스 객체이다.
- keys() 함수로 key값들을 조회
- 구성
- target_names: 예측하려는 값(class)을 가진 문자열 배열
- target: Label(출력데이터)
- data: Feature(입력변수)
- feature_names: 입력변수 각 항목의 이름
- DESCR: 데이터셋에 대한 설명
iris.keys() >>> dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])# 입력 데이터셋(Feature) print(type(iris.data), iris.data.shape) # scikit learn : Input/Output dataset ==> ndarray 를 사용. # input.shape(0축: 데이터포인트 개수, 한개 데이터포인트의 shape) # (150, 4) -> 150개의 데이터포인틀 구성된 데이터 셋. 1개의 데이터 포인트는 4개의 원소로 구성된 1 차원 배열. >>> <class 'numpy.ndarray'> (150, 4)- Feature(input) 조회
iris['feature_names'] # 각 Feature 가 어떤 값인지 설명.
>>>
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
- target(label) 조회
- input(features), output(labels)은 숫자(정수/실수) 여야 한다.
- 모델 - 알고리즘은 모두 계산하는 함수이기 때문이다.
# iris['target'] print(type(iris.target), iris.target.shape) print(np.unique(iris.target, return_counts = True)) >>> <class 'numpy.ndarray'> (150,) (array([0, 1, 2]), array([50, 50, 50]))iris.target_names >>> array(['setosa', 'versicolor', 'virginica'], dtype='<U10')print(iris.DESCR) >>> .. _iris_dataset: Iris plants dataset -------------------- Data Set Characteristics: :Number of Instances: 150 (50 in each of three classes) :Number of Attributes: 4 numeric, predictive attributes and the class :Attribute Information: - sepal length in cm - sepal width in cm - petal length in cm - petal width in cm - class: - Iris-Setosa - Iris-Versicolour - Iris-Virginica :Summary Statistics: ============== ==== ==== ======= ===== ==================== Min Max Mean SD Class Correlation ============== ==== ==== ======= ===== ==================== sepal length: 4.3 7.9 5.84 0.83 0.7826 sepal width: 2.0 4.4 3.05 0.43 -0.4194 petal length: 1.0 6.9 3.76 1.76 0.9490 (high!) petal width: 0.1 2.5 1.20 0.76 0.9565 (high!) ============== ==== ==== ======= ===== ==================== :Missing Attribute Values: None :Class Distribution: 33.3% for each of 3 classes. :Creator: R.A. Fisher :Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov) :Date: July, 1988 The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken from Fisher's paper. Note that it's the same as in R, but not as in the UCI Machine Learning Repository, which has two wrong data points. This is perhaps the best known database to be found in the pattern recognition literature. Fisher's paper is a classic in the field and is referenced frequently to this day. (See Duda & Hart, for example.) The data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant. One class is linearly separable from the other 2; the latter are NOT linearly separable from each other. .. topic:: References - Fisher, R.A. "The use of multiple measurements in taxonomic problems" Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to Mathematical Statistics" (John Wiley, NY, 1950). - Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis. (Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218. - Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System Structure and Classification Rule for Recognition in Partially Exposed Environments". IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. PAMI-2, No. 1, 67-71. - Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions on Information Theory, May 1972, 431-433. - See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II conceptual clustering system finds 3 classes in the data. - Many, many more ... - input(features), output(labels)은 숫자(정수/실수) 여야 한다.
📍 위 데이터 셋을 판다스 데이터프레임으로 구성
- 데이터 프레임 생성 후 데이터 확인

import pandas as pd
df = pd.DataFrame(iris.data, columns = iris.feature_names)
df.head()
# iris.target을 "species" 컬럼에 추가
df['species'] = iris.target
df.head()
# 각각의 "species" index 값에 iris의 target_names 값 적용 그리고 그것들을 "species_2" 컬럼 생성.
df['species_2'] = df['species'].apply(lambda x: iris.target_names[x])
# df.head()
# df.tail()
df.iloc[60:65]

df.info()
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float64
1 sepal width (cm) 150 non-null float64
2 petal length (cm) 150 non-null float64
3 petal width (cm) 150 non-null float64
4 species 150 non-null int64
5 species_2 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.2+ KB
df.columns
>>>
Index(['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)',
'petal width (cm)', 'species'],
dtype='object')
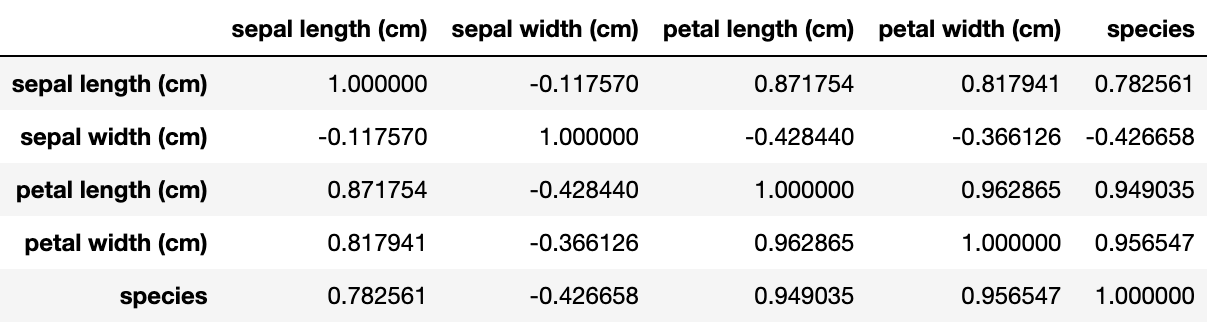
🌓 corr( ) 함수 재확인.
df[df.columns[:-1]].corr()
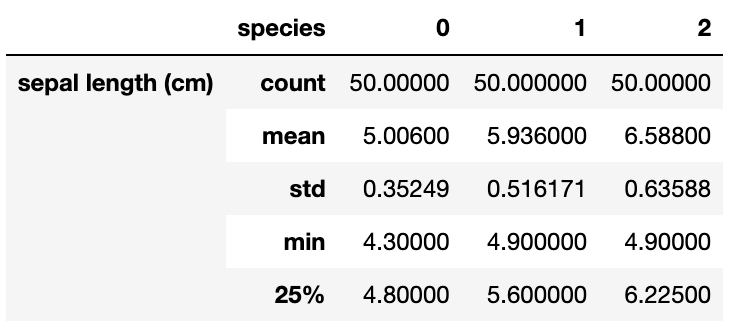
df[df.columns[:-1]].groupby('species').describe().T.head()
반응형
'[T.I.L] : Today I Learned > Machine Learning' 카테고리의 다른 글
| [ML] 2-3강_모델 추론 (0) | 2023.05.28 |
|---|---|
| [ML] 2-2강_머신러닝을 이용한 예측 (0) | 2023.05.28 |
| [ML] 1강_머신러닝 개요 (0) | 2023.05.28 |
'[T.I.L] : Today I Learned/Machine Learning' Related Articles
more


