
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- pandas filter
- Machine Learning
- 등비수열
- 기계학습
- 문제풀이
- 파이썬
- Folium
- 스터디노트
- plt
- MacOS
- INSERT
- python
- 순열
- SQL
- tree.fit
- 조합
- 리스트
- barh
- matplotlib
- numpy
- pandas
- DataFrame
- 통계학
- Slicing
- maplotlib
- 등차수열
- 재귀함수
- pandas 메소드
- 자료구조
- 머신러닝
Archives
- Today
- Total
코딩하는 타코야끼
[Pandas] 2-2강_Pandas DataFrame(행, 열의 값 조회 및 변경) 본문
[T.I.L] : Today I Learned/Pandas
[Pandas] 2-2강_Pandas DataFrame(행, 열의 값 조회 및 변경)
가스오부시 2023. 4. 13. 03:04728x90
반응형
1. 컬럼이름 / 행이름 조회 및 변경
📍 컬럼이름 / 행이름 조회
🌓 DataFrame객체.columns
- 컬럼명 조회
- 컬럼명은 차후 조회를 위해 따로 변수에 저장하는 것이 좋다.
movie.columns

🌓 DataFrame객체.index
- 행명 조회
movie.index
📍 컬럼이름 / 행이름 변경
- columns와 index 속성으로는 통째로 바꾸는 것은 가능하나 일부만 선택해서 변경하는 것은 안된다.
- df.columns = ['새이름','새이름', ... , '새이름']
- df.columns[1] = '새이름'
- 이런식으로 개별적으로 변경은 안된다.
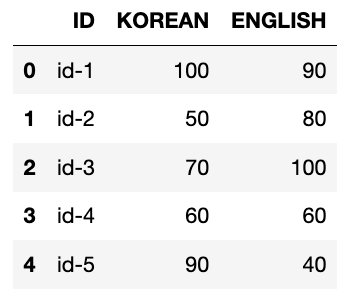
grade = pd.read_csv('saved_data/grade2.csv')
grade.columns

🌓 컬럼 원본 변경
grade.columns = ['ID', '국어', '영어'] # dataframe원본이 바뀜.
grade

🌓 개별 컬럼 변경 불가

🌓 컬럼이름 / 행이름 변경 관련 메소드
- DataFrame객체.rename(index=행이름변경설정, columns=열이름변경설정, inplace=False)
- 개별 컬럼이름/행이름 변경 하는 메소드
- 변경한 DataFrame을 반환
- 변경설정: 딕셔너리 사용
- {'기존이름':'새이름', ..}
- inplace: 원본을 변경할지 여부(boolean)
# 국어->KOREAN, 영어->ENGLISH new_columns = { "국어":"KOREAN", "영어":"ENGLISH" } new_index = { 0:'영', 1:'일', 2:'이', 3:'삼', 4:'사' } grade.rename(columns=new_columns, index=new_index, inplace=True) grade

- DataFrame객체.set_index(컬럼이름, inplace=False)
- 특정 컬럼을 행의 index 명으로 사용
- 열이 index명이 되면서 그 컬럼은 Data Set 에서 제거된다.
# ID 컬럼을\\ 행 식별자(index name)으로 지정. grade.set_index('ID', inplace= True) grade

- DataFrame객체.reset_index(inplace=False)
- index를 첫번째 컬럼으로 복원
grade.reset_index('ID', inplace = True)
# index명 생략 가능
# grade.resrt_index(inplace = True)
grade
2. 행과 열의 값 변경
📍 특정 행 또는 열 삭제
🌓 DataFrame객체.drop(columns, index, inplace=False)
- columns : 삭제할 열이름 또는 열이름 리스트
- index : 삭제할 index명 또는 index 리스트
- inplace: 원본을 변경할지 여부(boolean)
🌓 컬럼(열) 삭제
grade.drop(columns='KOREAN') # 1
grade.drop(columns=['KOREAN', 'ENGLISH']) # 2 - fancy
grade.drop(labels=['KOREAN', 'ENGLISH'], axis=1) # 3

🌓 index(행) 삭제
grade.drop(index = 2)
grade.drop(index = [0, 2, 4])
grade.drop(labels = [0, 2, 4], axis = 0)

📍 열 추가
- 새로운 열을 지정 후 값을 대입하면 새로운 열을 추가할 수 있다.
- 보통 파생변수를 만들 때 사용한다.
🌓 열 추가
- df['새열명'] = 값
- 마지막 열로 추가된다.
- 하나의 값을 대입하면 모든 행에 그 값이 대입된다.
- 다른 값을 주려면 배열에 담아서 대입한다.
# 컬럼값 조회
# 컬럼값 변경 df['컬럼명'] = 값 (없는 컬럼: 추가, 있는 컬럼: 변경)
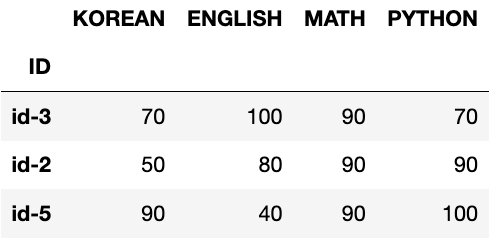
grade['MATH'] = 90
grade['PYTHON'] = [100, 90, 70, 80, 100]
grade

🌓 열 삽입
- df.insert(삽입할 위치 index, 삽입할 열이름, 값)
total = grade["KOREAN"] + grade["ENGLISH"] + grade["MATH"] + grade["PYTHON"]
grade.insert(3, "총점", total)
grade

🌓 파생변수생성
- 기존 열들의 값을 이용해서 만든 열을 파생변수라고 한다.
- 벡터화 연산을 이용하여 값 대입한다.
- df['새열이름'] = 기존 열들을 이용한 연산
3. 행, 열의 값 조회
- indexer 연산자를 이용한다.
- 행은 loc indexer, iloc indexer를 사용한다.
- 열은 indexing만 되고 slicing은 안된다.
- 행은 indexing, slicing 모두 지원한다.
📍 열의 값 조회
🌓 df['열이름']
- 열이름의 열 조회
🌓 df.열이름
- 열이름이 Python 식별자 규칙에 맞으면 . 표기법을 사용할 수 있다.
🌓 Fancy indexing
- 여러개의 열들을 한번에 조회할 경우 열이름들을 리스트로 묶어서 전달한다.
🌓 주의
- 열은 순번으로는 조회할 수 없다.
- 열 조회 indexer에서 슬라이싱을 하면 행 조회 Slicing이다.
- 만약 indexing이나 slicing을 이용해 열들을 조회하려면 columns 속성을 이용한다.
- df[df.columns[:3]]
- 만약 indexing이나 slicing을 이용해 열들을 조회하려면 columns 속성을 이용한다.
# 여러 컬럼 조회할때는 리스트로 묶어서 전달. -> fancy indexing
g2[['KOREAN', 'MATH']]

# 컬럼 순번으로 조회하려면 columns 를 이용.
col = g2.columns
g2[col[1:4]]

📍 다양한 열선택 기능을 제공하는 메소드들
🌓 select_dtypes(include=[데이터타입,..], exclude=[데이터타입,..])
- 전달한 데이터 타입의 열들을 조회.
- include : 조회할 열 데이터 타입
- exclude : 제외하고 조회할 열 데이터 타입
🌓 filter (items=[], like='', regex='')
- 매개변수에 전달하는 열의 이름에 따라 조회
- 각 매개변수중 하나만 사용할 수 있다.
- items = [컬럼명들, ..]
- 리스트와 일치하는 열들 조회
- 이름이 일치 하지 않아도 Error 발생안함.
- like = '부분일치문자열'
- 전달한 문자열이 들어간 열들 조회
- 부분일치 개념
- regex = '정규표현식'
- 정규 표현식을 이용해 열명의 패턴으로 조회
g.info()
>>>
<class 'pandas.core.frame.DataFrame'>
Index: 5 entries, id-1 to id-5
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 KOREAN 5 non-null int64
1 ENGLISH 5 non-null int64
2 MATH 5 non-null int64
3 PYTHON 5 non-null int64
4 총점 5 non-null int64
5 평균 5 non-null float64
dtypes: float64(1), int64(5)
memory usage: 280.0+ bytes
# 조회하려는 타입을 지정.
g.select_dtypes(include='float64')

🌓 행 조회
- loc : index 이름으로 조회
- iloc : 행 순번으로 조회
loc indexer
- index name으로 조회
- DF.loc[ index이름 ]
- 한 행 조회.
- 조회할 행 index 이름(레이블) 전달
- 이름이 문자열이면 " " 문자열표기법으로 전달. 정수이며 정수표기법으로 전달한다.
- DF.loc[ index이름 리스트 ]
- 여러 행 조회.
- 팬시 인덱스
- 조회할 행 index 이름(레이블) 리스트 전달
- DF.loc[start index이름 : end index이름: step]
- 슬라이싱 지원
- end index 이름의 행까지 포함한다.
- DF.loc[index이름 , 컬럼이름]
- 행과 열 조회
- 둘다 이름으로 지정해야 함.
# 행조회는 slicing 지원
g2.loc['id-2':'id-5'] # stop index도 포함
g2.loc['id-2':'id-5':2]
g2.loc['id-2':] # stop 생략 => 마지막 행까지 다 조회
g2.loc[:'id-3'] # start 생략=> 시작 행(0번 행) 부터 조회

g2.loc['id-2', 'KOREAN']
>>>
50
iloc
- index(행 순번)으로 조회
- DF.iloc[행번호]
- 한 행 조회.
- 조회할 행 번호 전달
- DF.iloc[ 행번호 리스트 ]
- 여러 행 조회.
- 조회할 행 번호 리스트 전달
- DF.iloc[start 행번호: stop 행번호: step]
- 슬라이싱 지원
- stop 행번호 포함 안함.
- DF.iloc[행번호 , 열번호]
- 행과 열 조회
- 행열 모두 순번으로 지정
# fancy indexing : list로 묶어서 전달
g2.iloc[[2,1,4]]
g.iloc[[1,3], [2, 5]]

g.iloc[[0, 3], : 4]

📍 Boolean indexing을 이용한 조회
- 원하는 조건을 만족하는 행, 열을 조회한다.
- DataFrame객체[조건], DataFrame객체.loc[조건]
- 조건이 True인 행만 조회
- 열까지 선택시
- DataFrame객체[조건][열]
- DataFrame객체.loc[조건, 열]
- iloc indexer는 boolean indexing을 지원하지 않는다.
- 논리연산자

- 논리연산자의 피연산자들은 반드시 ( )로 묶어준다
- 파이썬과는 다르게 and, or, not 예약어는 사용할 수 없다.
# 국어가 60 ~ 80 사이이고 영어가 100점인 행들의 국어, 영어, 평균점수를 확인
g2[g2['KOREAN'].between(60, 80) & (g2['ENGLISH'] == 100)][['KOREAN', 'ENGLISH', '평균']]
# df.loc[행->boolean index, 열]
g2.loc[g2['KOREAN'].between(60, 80) & (g2['ENGLISH'] == 100), ['KOREAN', 'ENGLISH', '평균']]

📍 query() 를 이용한 boolean indexing
🌓 query(조회조건)
- sql의 where 절의 조건 처럼 문자열의 query statement를 이용해 조건으로 조회
- boolean index에 비해
- 장점: 편의성(문자열로 query statement를 만들므로 동적 구문 생성등 다양한 처리가 가능)과 가독성이 좋다.
- 단점: 속도가 느리다.
🌓 조회조건 구문
- "컬럼명 연산자 비교값"
🌓 외부변수를 이용해 query문의 비교값을 지정할 수 있다.
- query 문자열 안에서 @변수명 사용
- f string이나 format() 함수를 이용해 query를 만들 수도 있다.
🌓 query 함수 연산자
- 비교 연산자
- ==, >, >=, <, <=, !=
import pandas as pd import numpy as np data_dict = { 'name':['김영수', '박영희', '오준호', '조민경', '박영희', '김영수'], 'age':[23, 17, 28, 31, 23, 17], 'email':['kys@gmail.com', 'pyh@gmail.com', 'ojh@daum.net', 'cmk@naver.com', 'pyh@daum.net', np.nan]} df = pd.DataFrame(data_dict) df

# 비교연산
# 나이가 17세인 사람
# df[df['age'] == 17]
df.query("age == 17") #조회대상데이터프레임.query("컬럼명 == 비교값")
df.query("age > 25")
df.query("age != 17")

- 결측치 비교
- 컬럼.isna(), isnull()
- 컬럼.notna(), notnull()
#결측치가 있는 행 df.query("email.isna()") # 대상컬럼.isnull(), isna() df.query("email.isnull()")

- 논리 연산자
- and, or, not
# 논리연산 -> and, or, not 을 사용가능. (&, |, ~ 사용가능.) df.query('not age < 25') df.query('~ (age < 25)')

- in 연산자
- in, ==
- not in, !=
- 비교 대상값은 리스트에 넣는다.
# 나이가 17과 23이 아닌 행을 조회 df.query('age!=17 and age!=23') # 동일한 컬럼으로 여러개의 값과 != 비교. df.query('age != [17, 23]') df.query('age not in [17, 23, 30, 40, 50]')

- Index name으로 검색
- 행의 index 이름으로 검색
df.query('index in [1,3,4]')

- 문자열 부분검색(sql의 like)
- 컬럼명.str.contains(문자열): 문자열을 포함하고 있는
- 컬럼명.str.startswith(문자열): 문자열로 시작하는
- 컬럼명.str.endswith(문자열): 문자열로 끝나는
- 문자열 부분검색을 할 컬럼에 결측치(NaN)이 있으면 안된다.
# name컬럼의 값들 중 "영희"를 포함한 행. df.query('name.str.contains("영희")')

# email이 결측치가 아닌행을 조회 -> 2. 조건을 조회
df.query('email.notnull()').query('email.str.endswith("com")') # (메소드, 함수) chaining

반응형
'[T.I.L] : Today I Learned > Pandas' 카테고리의 다른 글
| [Pandas] 4-2강_pivot_table 및 일괄처리 메소드 (0) | 2023.04.19 |
|---|---|
| [Pandas] 4-1강_groupby 관련 메소드 (0) | 2023.04.19 |
| [Pandas] 3강_Pandas 정렬 집계 (0) | 2023.04.18 |
| [Pandas] 2-1강_Pandas DataFrame(메소드) (0) | 2023.04.13 |
| [Pandas] 1강_Pandas Series (1) | 2023.04.11 |
'[T.I.L] : Today I Learned/Pandas' Related Articles
more



